山東易搜大數據集團
與眾不同 方能創(chuàng )造不同發(fā)布日期:2015-12-08
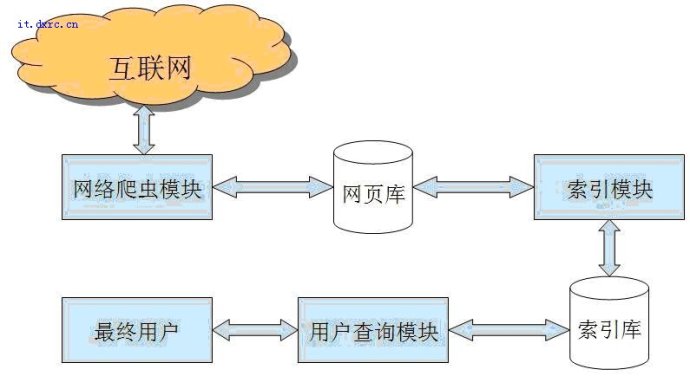
Spider抓取體系的根本結構
濟寧網(wǎng)絡(luò )公司在互聯(lián)網(wǎng)信息爆發(fā)式增加,怎么有用的獲取并使用這些信息是查找引擎作業(yè)中的首要環(huán)節。數據抓取體系作為全部查找體系中的上游,首要擔任互聯(lián)網(wǎng)信息的收集、保留、更新環(huán)節,它像蜘蛛相同在網(wǎng)絡(luò )間爬來(lái)爬去,因而一般會(huì )被叫做“spider”。例如咱們常用的幾家通用查找引擎蜘蛛被稱(chēng)為:Baiduspdier、Googlebot、SogouWeb Spider等。
濟寧網(wǎng)絡(luò )公司在Spider抓取體系是查找引擎數據來(lái)歷的重要確保,如果把web理解為一個(gè)有向圖,那么spider的作業(yè)進(jìn)程能夠認為是對這個(gè)有向圖的遍歷。從一些重要的種子URL開(kāi)端,經(jīng)過(guò)頁(yè)面上的超連接聯(lián)系,不斷的發(fā)現新URL并抓取,盡最大也許抓取到更多的有價(jià)值頁(yè)面。關(guān)于相似baidu這樣的大型spider體系,由于每時(shí)每刻都存在頁(yè)面被修正、刪去或呈現新的超連接的也許,因而,還要對spider曩昔抓取過(guò)的頁(yè)面堅持更新,保護一個(gè)URL庫和頁(yè)面庫。
下圖為spider抓取體系的根本結構圖,其間包含連接存儲體系、連接選擇體系、dns解析效勞體系、抓取調度體系、頁(yè)面剖析體系、連接獲取體系、連接剖析體系、頁(yè)面存儲體系。濟寧網(wǎng)絡(luò )公司對Baiduspider便是經(jīng)過(guò)這種體系的通力合作完成對互聯(lián)頁(yè)面面


售后響應及時(shí)
全國7×24小時(shí)客服熱線(xiàn)
硬件支持
更安全、更高效、更穩定
價(jià)格公道透明
全國統一價(jià),不弄虛作假
合作風(fēng)險小
重合同講信譽(yù),無(wú)效全額退款濟寧易搜信息科技有限公司
公司地址:濟寧市謝營(yíng)科技大廈10樓
公司座機:0537-2236968
售后服務(wù)熱線(xiàn):15269750111(微信同號)


















