山東易搜大數據集團
與眾不同 方能創(chuàng )造不同發(fā)布日期:2015-12-08
圖看似簡(jiǎn)略,但濟寧網(wǎng)絡(luò )公司對Baiduspider在抓取過(guò)程中面對的是一個(gè)超級雜亂的網(wǎng)絡(luò )環(huán)境,為了使體系能夠抓取到盡也許多的有價(jià)值資本并堅持體系及實(shí)踐環(huán)境中頁(yè)面的一致性一起不給網(wǎng)站體會(huì )形成壓力,會(huì )規劃多種雜亂的抓取戰略。以下做簡(jiǎn)略介紹:
1、抓取友好性
濟寧seo優(yōu)化資本無(wú)窮的數量級,這就需求抓取體系盡也許的高效運用帶寬,在有限的硬件和帶寬資本下盡也許多的抓取到有價(jià)值資本。這就形成了另一個(gè)疑問(wèn),消耗被抓網(wǎng)站的帶寬形成拜訪(fǎng)壓力,假如程度過(guò)大將直接影響被抓網(wǎng)站的正常用戶(hù)拜訪(fǎng)行動(dòng)。因而,在抓取過(guò)程中就要進(jìn)行必定的抓取壓力操控,到達既不影響網(wǎng)站的正常用戶(hù)拜訪(fǎng)又能盡量多的抓取到有價(jià)值資本的意圖。
一般狀況下,最基本的是依據ip的壓力操控。這是因為假如依據域名,也許存在一個(gè)域名對多個(gè)ip(許多大網(wǎng)站)或多個(gè)域名對應同一個(gè)ip(小網(wǎng)站同享ip)的疑問(wèn)。實(shí)踐中,一般依據ip及域名的多種條件進(jìn)行壓力分配操控。一起,站長(cháng)渠道也推出了壓力反應東西,站長(cháng)能夠人工分配對自個(gè)網(wǎng)站的抓取壓力,這時(shí)baiduspider將優(yōu)先依照站長(cháng)的需求進(jìn)行抓取壓力操控。
對同一個(gè)站點(diǎn)的抓取速度操控一般分為兩類(lèi):其一,一段時(shí)刻內的抓取頻率;其二,一段時(shí)刻內的抓取流量。同一站點(diǎn)不一樣的時(shí)刻抓取速度也會(huì )不一樣,例如夜深人靜月黑風(fēng)高時(shí)分抓取的也許就會(huì )快一些,也視詳細站點(diǎn)類(lèi)型而定,首要思維是錯開(kāi)正常用戶(hù)拜訪(fǎng)頂峰,不斷的調整。關(guān)于不一樣站點(diǎn),也需求不一樣的抓取速度。
2、常用抓取回來(lái)碼暗示
濟寧網(wǎng)絡(luò )公司簡(jiǎn)略介紹幾種baidu支撐的回來(lái)碼:
1)最常見(jiàn)的404代表“NOTFOUND”,以為頁(yè)面現已失效,一般將在庫中刪去,一起短期內假如spider再次發(fā)現這條url也不會(huì )抓取;
2)503代表“ServiceUnavailable”,以為頁(yè)面暫時(shí)不行拜訪(fǎng),一般網(wǎng)站暫時(shí)封閉,帶寬有限等會(huì )發(fā)生這種狀況。關(guān)于頁(yè)面回來(lái)503狀況碼,baiduspider不會(huì )把這條url直接刪去,一起短期內將會(huì )重復拜訪(fǎng)幾回,假如頁(yè)面已康復,則正常抓取;假如持續回來(lái)503,那么這條url仍會(huì )被以為是失效連接,從庫中刪去。
3)403代表“Forbidden”,以為頁(yè)面當前制止拜訪(fǎng)。假如是新url,spider暫時(shí)不抓取,短期內相同會(huì )重復拜訪(fǎng)幾回;假如是已錄入url,不會(huì )直接刪去,短期內相同重復拜訪(fǎng)幾回。假如頁(yè)面正常拜訪(fǎng),則正常抓取;假如依然制止拜訪(fǎng),那么這條url也會(huì )被以為是失效連接,從庫中刪去。
4)301代表是“MovedPermanently”,以為頁(yè)面重定向至新url。當遇到站點(diǎn)搬遷、域名替換、站點(diǎn)改版的狀況時(shí),咱們引薦運用301回來(lái)碼,一起運用站長(cháng)渠道網(wǎng)站改版東西,以削減改版對網(wǎng)站流量形成的丟失。
3、多種url重定向的辨認
在濟寧網(wǎng)站建設中一有些頁(yè)面因為各式各樣的緣由存在url重定向狀況,為了對這有些資本正常抓取,就需求spider對url重定向進(jìn)行辨認判別,一起避免做弊行動(dòng)。重定向可分為三類(lèi):http30x重定向、metarefresh重定向和js重定向。別的,baidu也支撐Canonical標簽,在作用上能夠以為也是一種直接的重定向。
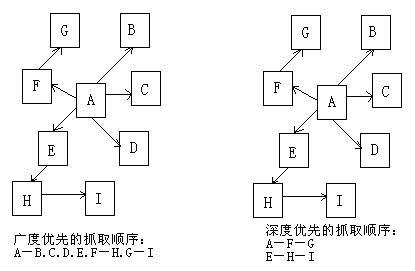
4、抓取優(yōu)先級分配
因為互聯(lián)網(wǎng)資本規劃的無(wú)窮以及敏捷的改變,關(guān)于搜索引擎來(lái)說(shuō)悉數抓取到并合理的更新堅持一致性幾乎是不也許的工作,因而這就需求抓取體系規劃一套合理的抓取優(yōu)先級分配戰略。首要包括:深度優(yōu)先遍歷戰略、寬度優(yōu)先遍歷戰略、pr優(yōu)先戰略、反鏈戰略、社會(huì )化共享輔導戰略等等。每個(gè)戰略各有好壞,在實(shí)踐狀況中一般是多種戰略聯(lián)系運用以到達最優(yōu)的抓取作用。
5、重復url的過(guò)濾
spider在抓取過(guò)程中需求判別一個(gè)頁(yè)面是不是現已抓取過(guò)了,假如還沒(méi)有抓取再進(jìn)行抓取頁(yè)面的行動(dòng)并放在已抓取網(wǎng)址調集中。判別是不是現已抓取其間涉及到最中心的是疾速查找并比照,一起涉及到url歸一化辨認,例如一個(gè)url中包括許多無(wú)效參數而實(shí)踐是同一個(gè)頁(yè)面,這將視為同一個(gè)url來(lái)對待。
6、暗網(wǎng)數據的獲取
濟寧網(wǎng)絡(luò )公司中存在著(zhù)許多的搜索引擎暫時(shí)無(wú)法抓取到的數據,被稱(chēng)為暗網(wǎng)數據。一方面,許多網(wǎng)站的許多數據是存在于網(wǎng)絡(luò )數據庫中,spider難以選用抓取頁(yè)面的方法取得完好內容;另一方面,因為網(wǎng)絡(luò )環(huán)境、網(wǎng)站自身不符合標準、孤島等等疑問(wèn),也會(huì )形成搜索引擎無(wú)法抓取。當前來(lái)說(shuō),關(guān)于暗網(wǎng)數據的獲取首要思路依然是經(jīng)過(guò)敞開(kāi)渠道選用數據提交的方法來(lái)處理,例如“baidu站長(cháng)渠道”“baidu敞開(kāi)渠道”等等。
7、抓取反做弊
spider在抓取過(guò)程中一般會(huì )遇到所謂抓取黑洞或許面對許多低質(zhì)量頁(yè)面的困惑,這就需求抓取體系中相同需求規劃一套完善的抓取反做弊體系。例如剖析url特征、剖析頁(yè)面巨細及內容、剖析站點(diǎn)規劃對應抓取規劃等等。


售后響應及時(shí)
全國7×24小時(shí)客服熱線(xiàn)
硬件支持
更安全、更高效、更穩定
價(jià)格公道透明
全國統一價(jià),不弄虛作假
合作風(fēng)險小
重合同講信譽(yù),無(wú)效全額退款濟寧易搜信息科技有限公司
公司地址:濟寧市謝營(yíng)科技大廈10樓
公司座機:0537-2236968
售后服務(wù)熱線(xiàn):15269750111(微信同號)


















